

This is a new language that all public health folks will require. There are lots of encyclopedias for Big Data: Dutch company Datfloq do a good one and the Big Data Made Simple portal has a useful one. What the generic lists do not do is bridge the gap between the technical terms and public health. Good news - we try to below. If you would like to suggest more, please do!
Algorithm. A mathematical formula or data driven routine for making predictions or supporting decisions. Public health people naturally think this way – just add in a lot more maths and coding.
API. An Application Programme Interface is a set of routines, protocols, and tools for building software applications - requirements that govern how one application can talk to another. Without this we would not be able to present data from lots of different health sources in one place.
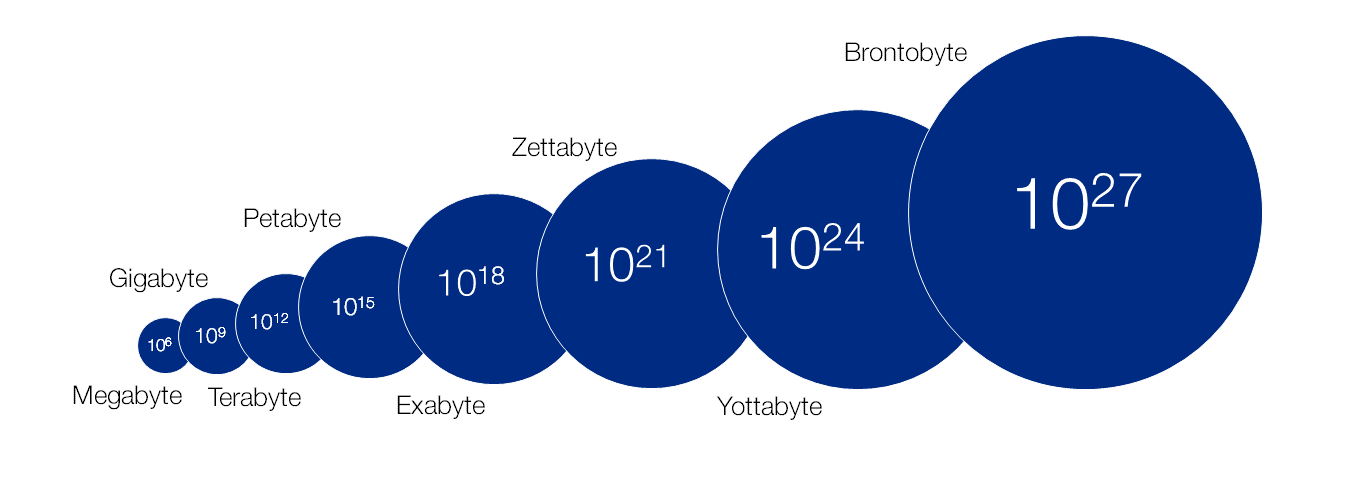
Big D Brontobyte. Not so long ago it took a plane to move a 5mb storage unit. As the size of data increases dramatically new terms are coined we now have the Brontobyte at 1027megabytes. Think electronic patients records, or social media data – how much more data are they generating – this is why we need brontobytes.
Clickstream Analytics. Can be used for example to gauge online shopping patterns or search engine choices – potentially useful as a measure of behavioural nudge programmes – interested in seeing if a healthy food swaps campaign has changed what people choose to put in their shopping carts? Now you can.
Data lake. This is a storage centre that can allow large amounts of disparate data to be stored in its raw form. Right now Public Health England largely stores silos of information that are then processed into indicators which are groomed and maintained. Shifting to storing the data itself and then streaming it into indicators could be more efficient, and allow more rapid border-free searching of the data store. Starting to do this with the Public Health England health profiles called Fingertips.
Data scraping. This extracts data from human readable formats – for example patient notes or web sites.
Dimensionality. Refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces (often with hundreds or thousands of dimensions) that do not occur in low-dimensional settings such as the three-dimensional physical space of everyday experience.
Git. Like other version control systems, manages and stores revisions of projects. Although it’s mostly used for code, Git can be used to manage any other type of file, such as Word documents or Final Cut projects. Think of it as a filing system for every draft of a document.
Gegabytes. Will follow Brontobytes – even bigger. Matt Damon said (referring to a fight scene) "It's a really cool sequence, ... With all those effects, yeah, it's pretty ..." I propose the Damonbyte to follow.
Governance. The overall management of the availability, usability, integrity, and security of the data employed in an enterprise – an emerging science for public health is how to do this well.
HADOOP. An open-source software framework, developed by Google, and written in Java for distributed storage and distributed processing of very large data sets. This means you do not have to keep them all in one place or in one format – it is schema free. Facebook uses it, so do most of the worlds major companies.
The Internet of Things (IoT) is the network of physical objects or "things" embedded with electronics, software, sensors, and network connectivity which enables these objects to collect and exchange data.
Linked data. Joining up data from different sources – standard public health approach writ large.
Machine learning. This is the science of getting computers to act without being explicitly programmed. Can allow faster processing of very large datasets and likely to automate many tasks in public health data processing and analysis.
Map reduce. A technique for analysing big data which splits data into smaller parts, applies analysis and recombines the results (split-apply-combine). The grizzly innards of data science!
Data Munging. It seems like a simple task: get data from one dataset to match up with, or in the same format as, data from other datasets. In fact it is messy and not clean, hence the term Data Munging which refers to the messy art and science of getting data from all different sources with different formats to connect to each other. It is about data problem solving. The term was coined in 1958 in the Tech Model Railroad Club at the Massachusetts Institute of Technology.[1] In 1960 the backronym "Mash Until No Good" was created to describe Mung, and a while after it was revised to "Mung Until No Good". The model train link is largely forgotten.
NewSQL– an elegant, well-defined database system that is easier to learn and better than SQL (a programming language for retrieving data from a relational database which is extensively used by public health analysts – a core skill). This just goes to show you how fast the field is moving!
Open science. The movement to make scientific research, data and dissemination accessible to all levels of an inquiring society. Underpins much of the philosophical thinking in Data Science and how it might be used to improve public health.
Predictive analytics. Using one set of data to make a prediction about the future or unknown data. Used a lot by Amazon for example to make recommendations, spam filters, or Google as part of Flu Trends. Often uses machine learning algorithms.
Privacy. Information or data privacy is the relationship between collection and dissemination of data, technology, the public expectation of privacy, and the legal and political issues surrounding them. (thank you Wikipedia!). Governance then becomes the challenge of how you manage this.

Python. Is an import programming language associated with Data Science. It’s free, it’s fast and it’s relatively easy to use. Increasingly, large applications are written almost exclusively in Python - from YouTube to NASA.
Query – asking a data system for information to answer a certain question
R is one of the leading tools for statistics, data analysis, and machine learning and widely used among statisticians and data miners. It is a programming language as well as a software environment for statistical computing and graphics.
Reproducible research. The idea that the data, code and results of research should be shared so that some one else can reproduce what a researcher does. Often uses a version control system like GIT, and software like R.
Stack. Hardware and software required for data processing and management or other tasks.
Text mining. Text can be data and can be analysed for patterns, associations, themes and so on. There are good tools in R and Python, and Voyant is a powerful online free tool for rapid analysis.
Tidy data. A normalized data set with one observation per row and one column per variable – a key step in analysis and an end point in data munging.
Unsupervised machine learning. A form of machine learning in which computers look for clustering or patterns in data. As opposed to supervised learning where computers are ‘trained’ on what to look for.
Vs (the 4). Big data is often characterized by 4Vs - volume, variety, velocity (real time data) and veracity (data quality) - and increasingly by a fifth – value. Soon to become standard epidemiology-speak. We hope.
Data Wrangling. See munging
Yottabyte. Huge data – 1000 zettabytes
Zettabyte. Big data – 1012 gigabytes.
Word cloud by Camelia.boban, via Wikimedia Commons
3 comments
Comment by RK posted on
Love this! Very helpful.
Comment by Mary E Black posted on
Thanks RK - did you spot the Matt Damon reference? Matt Damon is essential if you want to understand Big Data.
Comment by Julia Robson posted on
Thank you, this s extremely helpful. I am just amazed, however, at the names people have given digital things or processes - munging is possibly my favourite! 🙂